

目录
快速导航-

情报方法与技术创新 | 基于大小模型协同的情报学理论实体抽取研究
情报方法与技术创新 | 基于大小模型协同的情报学理论实体抽取研究
-

情报方法与技术创新 | 融合社交关系和知识图谱的双图注意力推荐模型
情报方法与技术创新 | 融合社交关系和知识图谱的双图注意力推荐模型
-

情报方法与技术创新 | 基于概念格融合模型的垃圾评论识别研究
情报方法与技术创新 | 基于概念格融合模型的垃圾评论识别研究
-
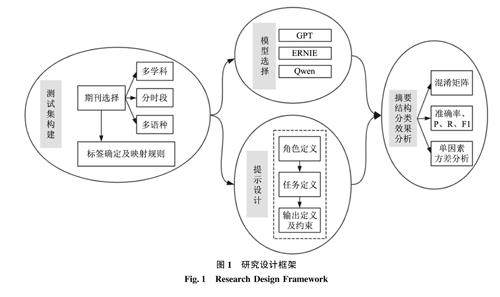
数据智能与知识服务 | 大语言模型在摘要结构功能识别上的应用研究
数据智能与知识服务 | 大语言模型在摘要结构功能识别上的应用研究
-
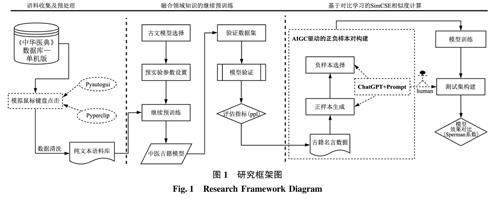
数据智能与知识服务 | 中医古文相似度计算研究:一种以生成式AI融合领域知识的SimCSE方法
数据智能与知识服务 | 中医古文相似度计算研究:一种以生成式AI融合领域知识的SimCSE方法
-
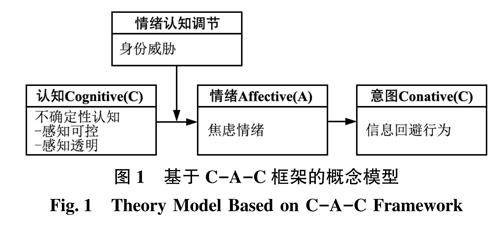
信息行为与用户研究 | 人工智能生成内容(AIG-C)信息回避影响机制研究
信息行为与用户研究 | 人工智能生成内容(AIG-C)信息回避影响机制研究
-

信息行为与用户研究 | 科研场景下人工智能生成内容用户采纳意愿的影响因素组态效应分析
信息行为与用户研究 | 科研场景下人工智能生成内容用户采纳意愿的影响因素组态效应分析
-
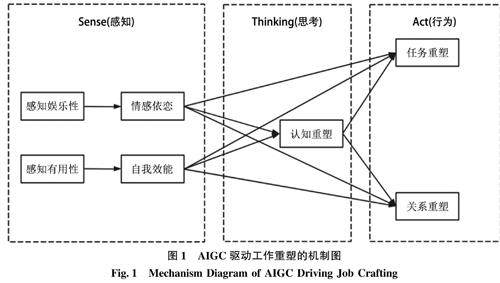
信息行为与用户研究 | AIGC如何“唤起”创作者(GCcr)工作重塑
信息行为与用户研究 | AIGC如何“唤起”创作者(GCcr)工作重塑
-
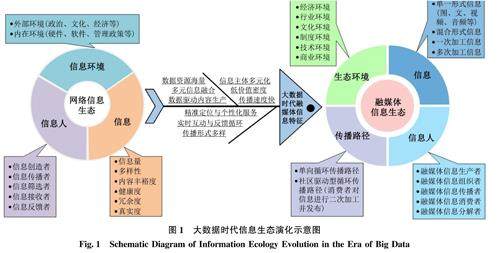
情报工作与情报事业 | 大数据时代融媒体信息生态研究与实证分析
情报工作与情报事业 | 大数据时代融媒体信息生态研究与实证分析
-
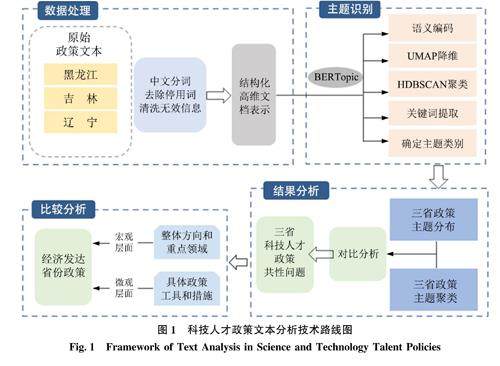
情报工作与情报事业 | 基于BERTopic的科技人才政策文本主题识别与量化分析
情报工作与情报事业 | 基于BERTopic的科技人才政策文本主题识别与量化分析
-
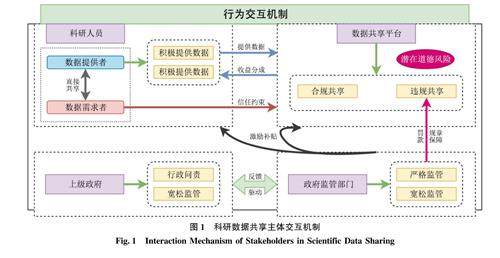
数据共享与数据治理 | 相关利益主体决策博弈行为对科研数据共享的影响研究
数据共享与数据治理 | 相关利益主体决策博弈行为对科研数据共享的影响研究
-
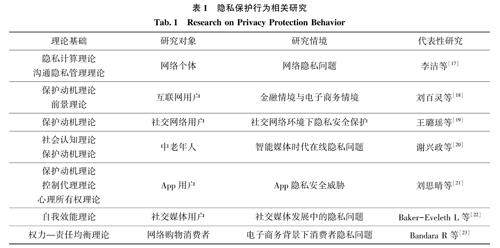
数据共享与数据治理 | 政府数据开放中用户隐私保护行为产生机制研究
数据共享与数据治理 | 政府数据开放中用户隐私保护行为产生机制研究
-

数智健康与智慧医养 | 在线健康知识服务中的用户健康赋能结构维度与量表开发研究
数智健康与智慧医养 | 在线健康知识服务中的用户健康赋能结构维度与量表开发研究
-
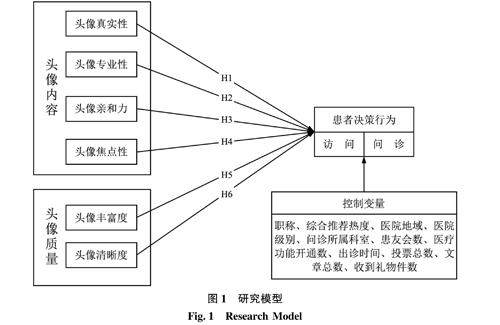
数智健康与智慧医养 | 自我呈现视角下医生头像信息对患者决策行为的影响研究
数智健康与智慧医养 | 自我呈现视角下医生头像信息对患者决策行为的影响研究












 登录
登录